1. 问题
公司数仓业务有一个 sql 任务,每天会产生大量的小文件,每个文件只有几百 KB~几 M 大小,小文件过多会对 HDFS 性能造成比较大的影响,同时也影响数据的读写性能(Spark 任务某些情况下会缓存文件信息),虽然开发了小文件合并工具会去定期合并小文件,但还是想从源头上来解决这个问题,尽量生成比较合适的文件大小,而不是事后补救。
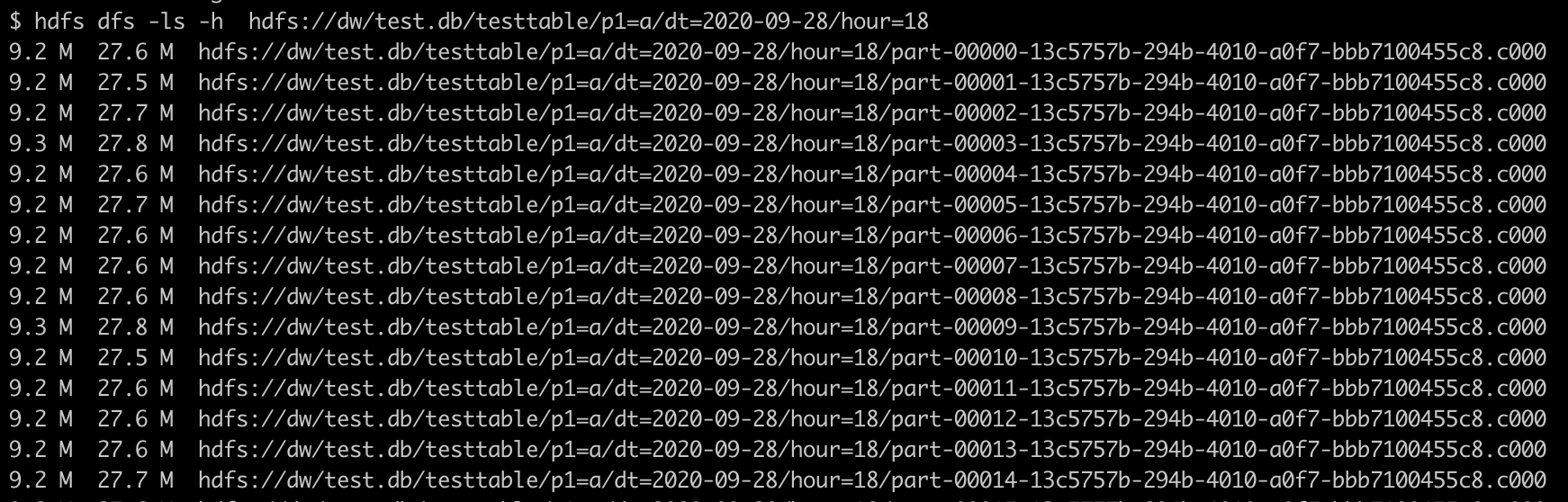
下图是优化前一天 18 点这个分区的数据,可以看出小文件问题明显。
2. 分析
思路:
1、统计每次生成的文件大小
2、每个小文件的大小
3、预期文件大小
4、找到优化方法,使其满足预期大小
统计一下每个分区的数据量,差不多每个小时 1-6G 数据
$ hdfs dfs -du -h hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/
3.4 G 10.2 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=00
2.1 G 6.3 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=01
1.4 G 4.3 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=02
1.1 G 3.4 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=03
1.2 G 3.6 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=04
1.8 G 5.5 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=05
3.1 G 9.3 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=06
3.8 G 11.4 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=07
3.8 G 11.5 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=08
3.9 G 11.6 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=09
4.1 G 12.2 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=10
4.6 G 13.7 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=11
5.4 G 16.3 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=12
4.7 G 14.0 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=13
4.1 G 12.4 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=14
4.1 G 12.3 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=15
4.1 G 12.4 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=16
4.5 G 13.4 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=17
4.6 G 13.8 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=18
5.0 G 15.1 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=19
5.5 G 16.6 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=20
6.1 G 18.4 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=21
6.2 G 18.7 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=22
5.0 G 15.1 G hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=23
使用 hour=18 这个分区举例:
$ hdfs dfs -ls -h -R hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=18|wc -l
800
可以看出有 800 个文件。
详细看一下文件大小,有一半是 9.2M 左右和一半2.6M左右(实际是由 UNION ALL 分别生成 400个 ),其他就不列出来了.
9.2 M 27.6 M hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=18/part-00397-13c5757b-294b-4010-a0f7-bbb7100455c8.c000
9.3 M 27.8 M hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=18/part-00398-13c5757b-294b-4010-a0f7-bbb7100455c8.c000
9.2 M 27.5 M hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=18/part-00399-13c5757b-294b-4010-a0f7-bbb7100455c8.c000
2.6 M 7.7 M hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=18/part-00400-13c5757b-294b-4010-a0f7-bbb7100455c8.c000
2.6 M 7.7 M hdfs://dw/test.db/testtable/p1=a/dt=2020-09-28/hour=18/part-00401-13c5757b-294b-4010-a0f7-bbb7100455c8.c000
文件由 SQL ETL 生成,清洗入库的sql 如下:
INSERT
overwrite TABLE testdb.testtable PARTITION (p1, dt, hour)
SELECT
...
FROM
t1
UNION ALL
SELECT
...
FROM
t2
上面是很典型的一个业务,定时向某个时间点的分区导入数据。
从上面的sql 可以看出 2 个重要信息:
1、数据表有三个分区字段 p1,dt,hour 其中 dt 表示日期,hour 表示小时.
2、 insert overwrite SELECT 导入,有 1 个 UNION ALL
应该是每个SELECT 有 400 个 partition 导致 2 个表 UNION ALL 加起来一共 800 个文件。
我们理想的文件大小是保持在100-200M(建议略小于等于BLOCK 大小),比如HDFS BLOCK为128MB,则可以按照100M左右去算。
目前每小时是1-6G数据量。
3. 优化
Spark SQL 支持 使用 ` /*+ REPARTITION(N) */ ` hint 来重新 repartition 数据,
按照每个分区1-6 G 的数据量,设置 40/20个PARTITION
INSERT
overwrite TABLE testdb.testtable PARTITION (a, dt, hour)
SELECT
/*+ REPARTITION(40) */
...
FROM
t1
UNION ALL
SELECT
/*+ REPARTITION(20) */
...
FROM
t2
优化以后,我们发现今天新生成的数据文件明显变大,大小都在95M 左右,小文件问题解决了。
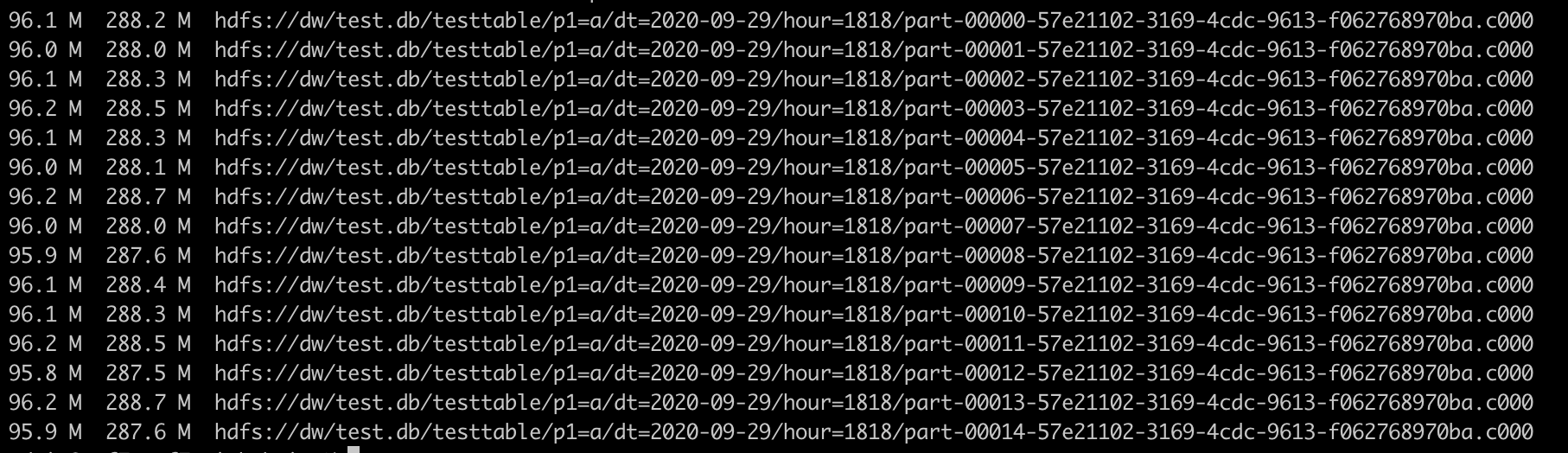
有一个奇怪的点,优化以后数据量会比以前大一些,大概会多5%-10% ,数据表格式是ORC, 按常理来说,ORC 合并的话,应该会稍微小一点,或者基本上没有变化,因为 ORC 里面有很多统计信息或者如果更多相同的数据,可以编码压缩掉,经过研究,发现应该是 repartition 是会重新做一次全量的shuffle,这样的话,不利于 ORC 编码和压缩,除了 REPARTITION,Spark 的 Partition 还支持 COALESCE ,我们可以使用COALESCE 来替代REPARTITION.
Partitioning Hints Types
- COALESCE
The
COALESCEhint can be used to reduce the number of partitions to the specified number of partitions. It takes a partition number as a parameter.
- REPARTITION
The
REPARTITIONhint can be used to repartition to the specified number of partitions using the specified partitioning expressions. It takes a partition number, column names, or both as parameters.
- REPARTITION_BY_RANGE
The
REPARTITION_BY_RANGEhint can be used to repartition to the specified number of partitions using the specified partitioning expressions. It takes column names and an optional partition number as parameters.
关于 coalesce 与 repartition 的区别,请参考链接[3]:
The repartition algorithm does a full shuffle of the data and creates equal sized partitions of data. coalesce combines existing partitions to avoid a full shuffle.
实际上翻阅代码可以得到,RDD 的 repartition 就是调用的 coalesce 函数,只是shuffle 参数设置为了true,我们的目的是减少小文件,所以这块可以使用 coalesce 。
/**
* Return a new RDD that has exactly numPartitions partitions.
*
* Can increase or decrease the level of parallelism in this RDD. Internally, this uses
* a shuffle to redistribute data.
*
* If you are decreasing the number of partitions in this RDD, consider using `coalesce`,
* which can avoid performing a shuffle.
*/
//这里的repartion 调用了 coalesce 函数,然后 shuffle 参数设置了true
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
/**
* Return a new RDD that is reduced into `numPartitions` partitions.
*
* This results in a narrow dependency, e.g. if you go from 1000 partitions
* to 100 partitions, there will not be a shuffle, instead each of the 100
* new partitions will claim 10 of the current partitions. If a larger number
* of partitions is requested, it will stay at the current number of partitions.
*
* However, if you're doing a drastic coalesce, e.g. to numPartitions = 1,
* this may result in your computation taking place on fewer nodes than
* you like (e.g. one node in the case of numPartitions = 1). To avoid this,
* you can pass shuffle = true. This will add a shuffle step, but means the
* current upstream partitions will be executed in parallel (per whatever
* the current partitioning is).
*
* @note With shuffle = true, you can actually coalesce to a larger number
* of partitions. This is useful if you have a small number of partitions,
* say 100, potentially with a few partitions being abnormally large. Calling
* coalesce(1000, shuffle = true) will result in 1000 partitions with the
* data distributed using a hash partitioner. The optional partition coalescer
* passed in must be serializable.
*/
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")
if (shuffle) {
/** Distributes elements evenly across output partitions, starting from a random partition. */
val distributePartition = (index: Int, items: Iterator[T]) => {
var position = new Random(hashing.byteswap32(index)).nextInt(numPartitions)
items.map { t =>
// Note that the hash code of the key will just be the key itself. The HashPartitioner
// will mod it with the number of total partitions.
position = position + 1
(position, t)
}
} : Iterator[(Int, T)]
// include a shuffle step so that our upstream tasks are still distributed
new CoalescedRDD(
new ShuffledRDD[Int, T, T](
mapPartitionsWithIndexInternal(distributePartition, isOrderSensitive = true),
new HashPartitioner(numPartitions)),
numPartitions,
partitionCoalescer).values
} else {
new CoalescedRDD(this, numPartitions, partitionCoalescer)
}
}
最后优化的SQL 语句
INSERT
overwrite TABLE testdb.testtable PARTITION (a, dt, hour)
SELECT
/*+ COALESCE(40) */
...
FROM
t1
UNION ALL
SELECT
/*+ COALESCE(20) */
...
FROM
t2
修改以后,发现数据量基本上于以前保持一致。
思考:
- 为什么之前会有 800 ( 400+400 ) 个
partition? - 是否通过设置如下参数
spark.sql.shuffle.partitions=40解决这个问题,区别是什么? - repartition 与 coalesce 区别是什么?
- Spark 有几种 repartition 方法
参考链接
- https://spark.apache.org/docs/3.0.1/sql-ref-syntax-qry-select-hints.html
- https://medium.com/@mrpowers/managing-spark-partitions-with-coalesce-and-repartition-4050c57ad5c4#.36o8a7b5j
- https://stackoverflow.com/questions/54218006/why-does-the-repartition-method-increase-file-size-on-disk